preparation
pip reinstall
uninstall current pip
apt-get install python-pip #which install the default 8.1 version
sudo -H pip2 install –upgrade pip #which upgrade to 20.1 version
|
|
why does pip3 say I am using v8.1.1, however version 20.1.1 is avail
install asammdf
it’s recommended to use conda env to manage this project. name this env as mdf. it’s recommended to install packages through conda install, rather than system apt-get install.
the following packages is required:
|
|
take care the pkg installed path, either globally in conda/pkgs/ or in the special env /conda/envs/mdf/lib/python3/site-packages, can simplely import asammdf to see $PYTHONPATH found the module.
conda pythonpath
check existing system path.
|
|
PYTHON loads the modules from the sys.path in the order, so if PYTHON find the required module in the first PATH, which however is the wrong version, then it’s an error.
does anaconda create a separate PYTHONPATH for each new env: each environment is a completely separate installation of Python and all the packages. there’s no need to mess with PYTHONPATH because the Python binary in the environment already searches the site-packages in that environment, and the libs of the environment.
in one word, when using conda, don’t use system PYTHONPAH
install asammdf[gui]
- test with PyQt5
|
|
reports Could not load the Qt platform plugin “xcb” in “” even though it was found
the reason is due to libqxcb.so from ~/anaconda3/envs/aeb/lib/python3.6/site-packages/PyQt5/Qt/plugins/platforms not found libxcb-xinerama.so.0, fixed by install libxcb-xinerama0
|
|
- install
|
|
|
|
numpy utils
- output precision
|
|
asammdf
bypass non-standard msg
most OEM mdf4 files are collected by Vector CANape tools, which may include many uncommon types, such as Matlab/Simulink objects, measurement signals(multimedia) cam-stream e.t.c, which can’t be parsed by current asammdf tool.
so a simple fix is to bypass these uncommon data type, submit in the git issue.
bytes object to numerical values
bytes objects basically contain a sequence of integers in the range 0-255, but when represented, Python displays these bytes as ASCII codepoints to make it easier to read their contents.
Because a bytes object consist of a sequence of integers, you can construct a bytes object from any other sequence of integers with values in the 0-255 range, like a list:
|
|
in asammdf, the numerical ndarray can be stored as uint8, uint32, uint64 e.t.c, but with a different range and representation. for radar/camera detected obj id, the range is in [0~255], so here need output as uint8.
sample of ObjID as asammdf.Signal:
|
|
mf4_reader
first, we need define a high-level APIs to handle collected mf4 from road test. which often includes a bunch of groups for each sensor, and a few channels to record one kind of Signal in one sensor. and another dimension is time, as each Signal is a time serial. the sample Signal output also shows there are two np.narray: samples and timestamps.
|
|
what we need is to repackage the signals from mf4 as structures of input(mostly like sensor packages) and output(another structure or CAN package) to any model required, e.g. fusion/aeb.
- init_multi_read(group_name, channel_nums, obj_nums, channel_list)
channel_nums, gives the number of channels/signals for this sensor
obj_nums, is the number of objects can detected by a special sensor, which is given by the vendor of the sensor. e.g. Bosch 5th Radar can detect at most 32 objects.
channel_list, is the name list of the channels, whose length should equal channel_nums.
this API does read all required channels raw data into memeory initially.
- updateCacheData(group_name, time)
time is the given timestamp, this API returns the interested samples at the given time. one trick here is time matching, as very possiblly, the given time doesn’t match any of the recorded timestamp in a special channel, here always seek the most closest timestamp to time.
seek_closest_timestamp_index(timestamps, time)
get_channel_data_by_name(channel_name, time)
get_channel_all_data_by_name(channel_name)
|
|
fusion adapter
once we can read all raw signals from mf4 files, then need to package these signals as the upper-level application requires. e.g. fusion, aeb input structs.
taking fusion module as example. the input includes radar structure, camera structure, e.t.c, something like:
|
|
data collection is done by Vector CANape, the sensor pack is defined in *.dbc file, so here basically does package dbc signals to a Python sensor_object, and then assign this sensor_object with the values from mdf4 files.
we need define a bunch of fusion_adapter to package all the necessary inputs for each module, e.g. fusion, aeb e.t.c
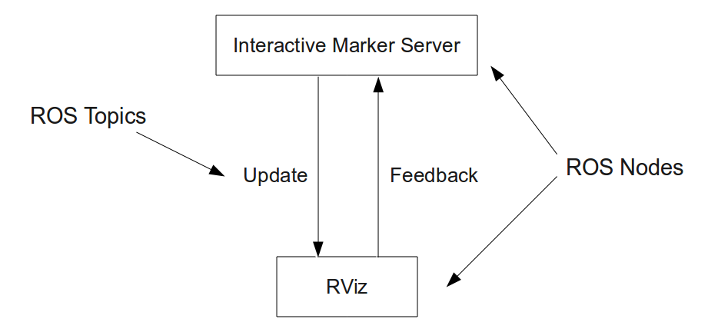
rosAdapter
another kind of usage from mf4 file, is transfer mf4 to rosbag. due to most ADS dev/debug/verifcation tools currently are based on ros env. on the other hand, ros base data collection is not robost enough than CANape, so the data collection is in *.mf4.
- build ros message and define ros_sensor_obj
as asammdf reader is in python, here can build ros message into python module, as mentioned prevously. as ros message built is with catkin_make, which is based on python2.7, so need add the sensor_msgs python module path to $PYTHONPATH in the conda env fusion.
|
|
basically, we use python3 shell, but we add the catkin_ws/python2.7 to its PYTHONPATH.
- write rosbag
then we can fill in ros_sensor_obj from mf4 structures. and write to bag.
|
|
rosbag know-how
|
|