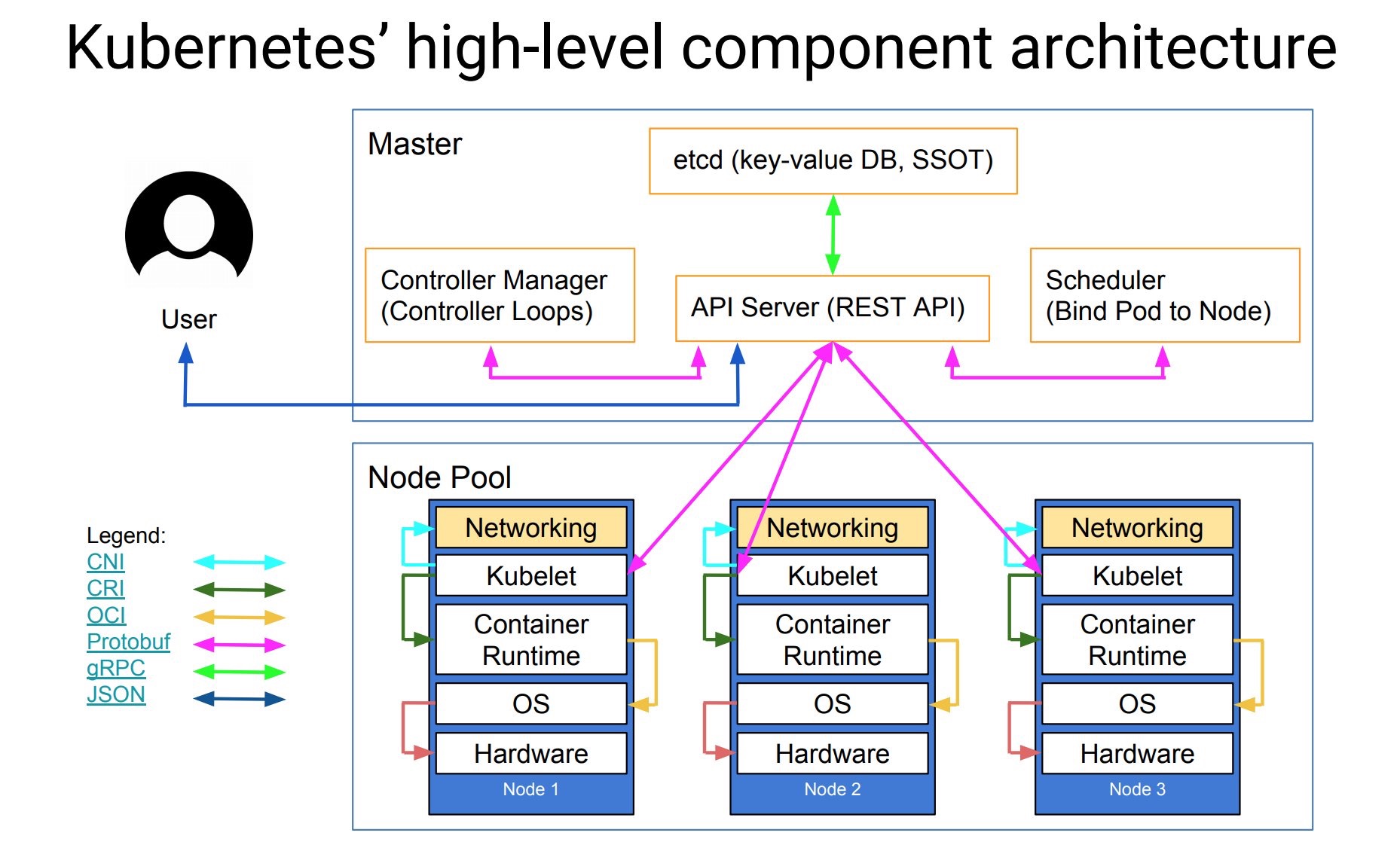
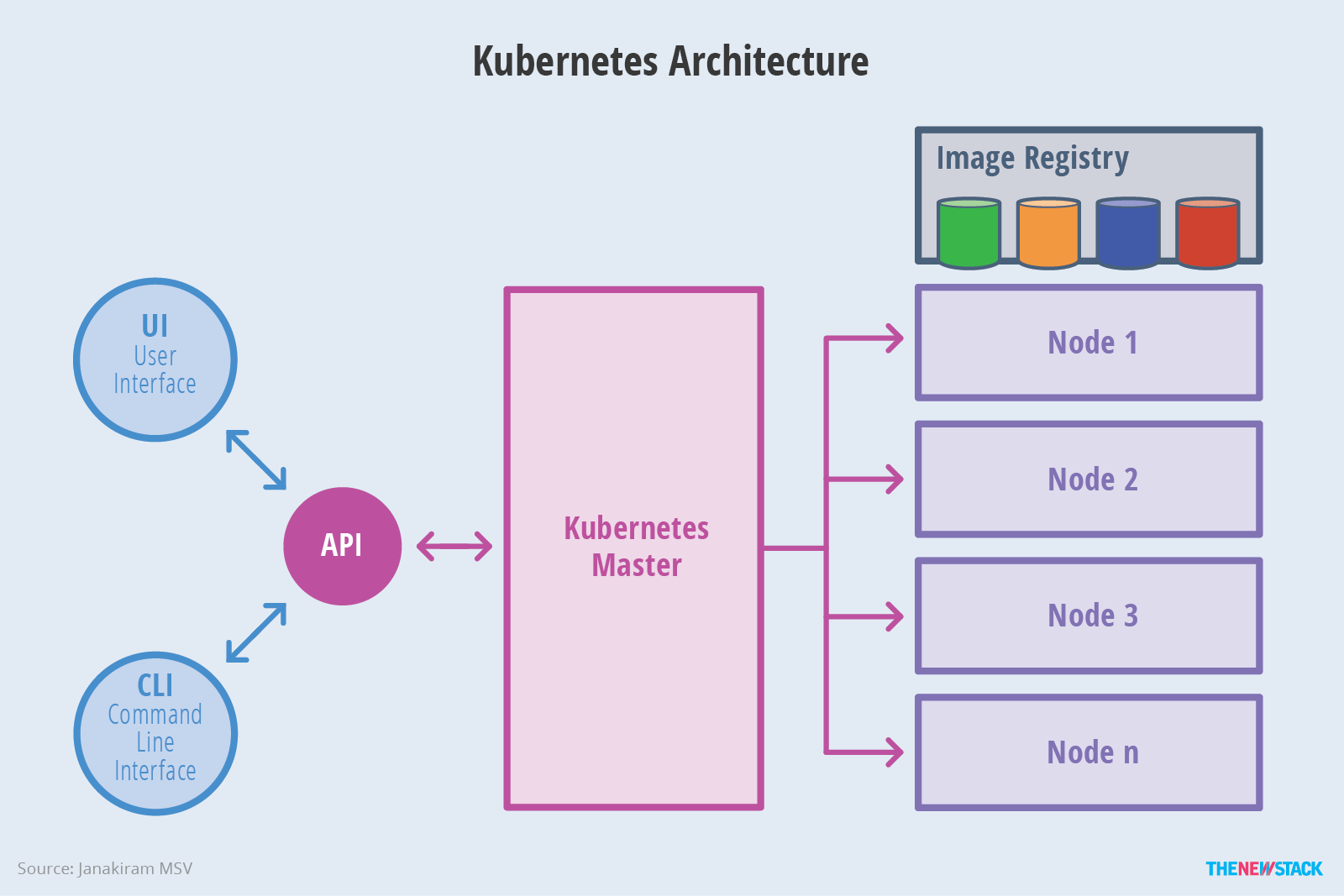
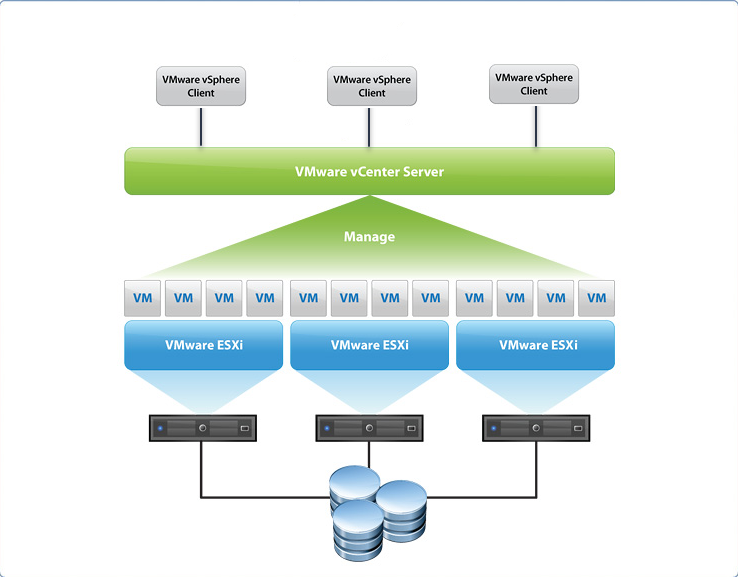
background
transfer from docker swarm to K8S finally. this is a lot engineering work, once have some knowledge about docker/swarm. there are two things:
a more general abstract object. e.g. pod, service/svc, deployment, secret, namespace/ns, role e.t.c.
more DevOps engineering
previously, I palyed with k8s in theory. this time is more about build a k8s cluster in reality.
install kubeadm
kubeadm, used to initial cluster
kubectl, the CLI tool for k8s
kubelet, run on all nodes in the cluster
all three commands are required on all nodes. check install kube officially
- swapoff
|
|
- create a file
/etc/apt/sources.list.d/kubernetes.listwith the following content:
|
|
- add gpg key
|
|
- apt install
|
|
tips, apt-get install will install v1.18.2.
- restart kubelet
|
|
if need degrade to v17.3, do the following:
|
|
kubeadm setup
we setup k8s with kubeadm tool, which requires a list of images:
- check the required images to start kubeadm
|
|
which returns:
|
|
the image source above is not aviable, which can be solved by:
|
|
if the command above doesn’t work well, try to docker pull directly and tag the name back to k8s.gcr.io:
|
|
start a k8s cluster
after the preparation above, finally start a k8s cluster as:
|
|
futher, check kubeadm init options:
|
|
cluster_dns option is used as the cluster DNS/namespace, which will be used in the configureMap for coreDNS forwarding.
if start successfully,
- then run the following as a regular user to config safety-verficiation:
|
|
- check
|
|
add pod network
pod network, is the network through which the cluster nodes can communicate with each other.
|
|
- worker node to join the new k8s cluster :
|
|
then cp flannel-cni.conflist into worker node. /etc/cni/net.d/10-flannel.conflist to the same path in worker node.
if check sudo kubectl get pods -n kube-system : there may come an error: here found: coredns CrashLoopBackOff or Error
this is due to DNS/nameserver resolving issue in Ubuntu, wherecoreDNS serviceforwarding the k8s cluster service to the host/etc/resolv.conf, which only has127.0.0.1`. the cause for CoreDNS to have CrashLoopBackOff is when a CoreDNS Pod deployed in Kubernetes detects a loop. A number of workarounds are available to avoid Kubernetes trying to restart the CoreDNS Pod every time CoreDNS detects the loop and exits.
check the coreDNS configMap by :
|
|
we see something like:
|
|
so modify forward line to forward . 10.3.0.10. or to delete loop service there, which is not good idea.
test cluster
clear cluster
|
|
understand CNI (container network interface)
the following network plugin can be found from k8s cluster networking
- backgroud
container network is used to connect (container itself) to other containers, host machine or external network. container in runtime has a few network mode:
|
|
CNI brings a general network framework, used to manage network configure and network resources.
coreDNS
first, run coreDNS as a service in the cluster. then, update kubelet parameters to include IP of coreDNS and the cluster domain.
if there is no existing running Kube-DNS, or need a different CLusterIP for CoreDNS, then need update kubelet configuration to set cluster_dns and cluster_domain appropriately, which can be modified at:
/etc/systemd/system/kubelet.service/10-kubeadm.conf with additional options appending at kubelet line :
|
|
- restart kubelet service
|
|
flannel mis-usage
in the settings above, I manually copy flannel-cni.conflist and /run/flannel/subnet.env to worker node every time, whenever reboot the worker node. if else, the cluster bother the worker node is NotReady. as we deploy the cluster with kubectl, which is kind of a swarm service deploy tool. so the right way to use flannel should have all k8s.gcr.io/kube-proxy, quay.io/coreos/flannel images at worker node as well.
for version1.17+, flannel replace the default kube-proxy, but it still requires to have kube-proxy running in each node(kubelet).
after restart kubelet, checking pods -n kube-system, it shows kube-proxy and flannel on each node has a Running status. coreDNS services has run the same size of copies as the number of nodes, but we can find that all of them are running on leader node.
understand pod in k8s
accessing k8s pods from outside of cluster
- hostNetwork: true
this option applies to k8s pods, which work as --network=host in docker env.
options can used for create pod: name command args env resources ports stdin tty
create pod/deployment using yaml
k8s task1: define a command and args for a container
templating YAML in k8s with real code
but hostNetwork is only yaml supported
- hostPort
the container port is exposed to the external network at
|
|
hostPort allows to expose a single container port on the hostIP. but the hostIP is dynamic when container restarted
- nodePort
by default, services are accessible at ClusterIP, which is an internal IP address reachable from inside the cluster. to make the service accessible from outside of the cluster, can create a NodePort type service.
once this service is created, the kube-proxy, which runs on each node of the cluster, and listens on all network interfaces is instructed to accept connections on port 30000, (from any IP ?). the incoming traffc is forwardedby the kube-proxy to the selected pods in a round-robin fashion.
this service represents a static endpoint through which the selected pods can be reached.
- Ingress
The Ingress controller is deployed as a Docker container on top of Kubernetes. Its Docker image contains a load balancer like nginx or HAProxy and a controller daemon.
view pods and nodes
- check running pods on which node
resolv.conf in k8s pod
run as interactive into a k8s pod, then check its resolv.conf:
|
|
10.96.0.10 is the K8S DNS server IP, which is actually the service IP of kube-dns service.
interesting, we can ping neither 10.96.0.10, nor 10.4.0.10, which is not existing service in the cluster, nor 10.3.0.10, which is the coreDNS forwarding IP.
remember during setup the k8s cluster, we had define the coreDNS forwarding to 10.3.0.10, is this why I can’t run curl http://<ip>:<port> works ?
check coreDNS service:
|
|
when start coreDNS, is actually used to relace kube-dns.
understand service in k8s
Each Pod gets its own IP address, however in a Deployment, the set of Pods running in one moment in time could be different from the set of Pods running that application a moment later.
A Service in Kubernetes is a REST object, similar to a Pod. you can POST a Service definition to the API server to create a new instance.
Kubernetes assigns this Service an IP address, sometimes called the clusterIP,
Virtual IP and service proxies
Every node in a Kubernetes cluster runs a kube-proxy, kube-proxy is responsible for implementing a form of virtual IP for Services, whose is type is any but not ExternalName.
choosing own IP for service
You can specify your own cluster IP address as part of a Service creation request. The IP address that you choose must be a valid IPv4 or IPv6 address from within the service-cluster-ip-range CIDR range that is configured for the API server
discovering services
ENV variables
DNS
headless services
by explicitly specifying “None” for the cluster IP (.spec.clusterIP).
publishing services(ServiceTypes)
expose a service to an external IP address, outside of the cluster.
service has four type:
ClusterIP (default): expose the service on a cluster-internal IP, which is only reachable inside the cluster
NodePort: expose the service on each node’s IP at a static port(
NodePort), to access :: ExternalName: map the services to an
externalNameLoadBalancer: expose the service externally using third-party load balancer(googl cloud, AWS, kubeadm has none LB)
NodePort and LoadBalancer can expose service to public, or outside of the cluster.
external IPs
if there are external IPs that route to one or more cluster nodes, services can be exposed on those externalIPs.
yaml deployment of service/pod
the previous sample busybox, is running as pod, through kubectl run busybox ? so there is no external
- using yaml file to create service and expose to public
some basic knowledge:
1) pod is like container in docker, which assigned a dynamic IP in runtime, but this pod IP is only visible inside cluster
2) service is an abstract concept of pod, which has an unique exposed IP, and the running pods belong to this service are managed hidden.
both pod and deployment are full-fledged objects in k8s API. deployment manages creating Pods by means of ReplicaSets, namely create pods with spec taken from the template. since it’s rather unlikely to create pods directly in a production env.
in production, you will almost never use an object with the type pod. but a deployment object, which needs to keep the replicas(pod) alive. what’s use in practice are:
1) Deployment object, where to specify app containers with some specifications
2) service object
you need service object since pods from deployment object can be killed, scaled up and down, their IP address is not persistent.
kubectrl commands
|
|
kubectl is pretty much like docker command and more.
refere
blog: setup k8s on 3 ubuntu nodes