background
to deploy simulation in docker swarm, there is a hurting that GPU rendering in docker requires a physical monitor(as $DISPLAY env variable). which is due to GeForece(Quadro 2000) GPUs, for Tesla GPUs there is no depends on monitor. really intertesting to know.
there were two thoughts how to deploy simulation rendering in cloud, either a gpu rendering cluster, or a headless mode in container cluster.
unity rendering
unity rendering pipeline is as following :
CPU calculate what need to draw and how to draw
CPU send commands to GPU
GPU plot
direct rendering
for remote direct rendering for GLX/openGL, Direct rendering will be done on the X client (the remote machine), then rendering results will be transferred to X server for display. Indirect rendering will transmit GL commands to the X server, where those commands will be rendered using server’s hardware.
|
|
Direct Rendering Infrasturcture(DRI) means the 3D graphics operations are hardware acclerated, Indirect rendering is used to sya the graphics operations are all done in software.
DRI enable to communicate directly with gpus, instead of sending graphics data through X server, resulting in 10x faster than going through X server
for performance, mostly the games/video use direct rendering.
headless mode
to disable rendering, either with dummy display. there is a blog how to run opengl in xdummy in AWS cloud; eitherwith Unity headless mode, When running in batch mode, do not initialize graphics device at all. This makes it possible to run your automated workflows on machines that don’t even have a GPU. to make a game server running on linux, and use the argument “-batchmode” to make it run in headless mode. Linux -nographics support -batchmode is normally the headless flag that works without gpu and audio hw acceleration
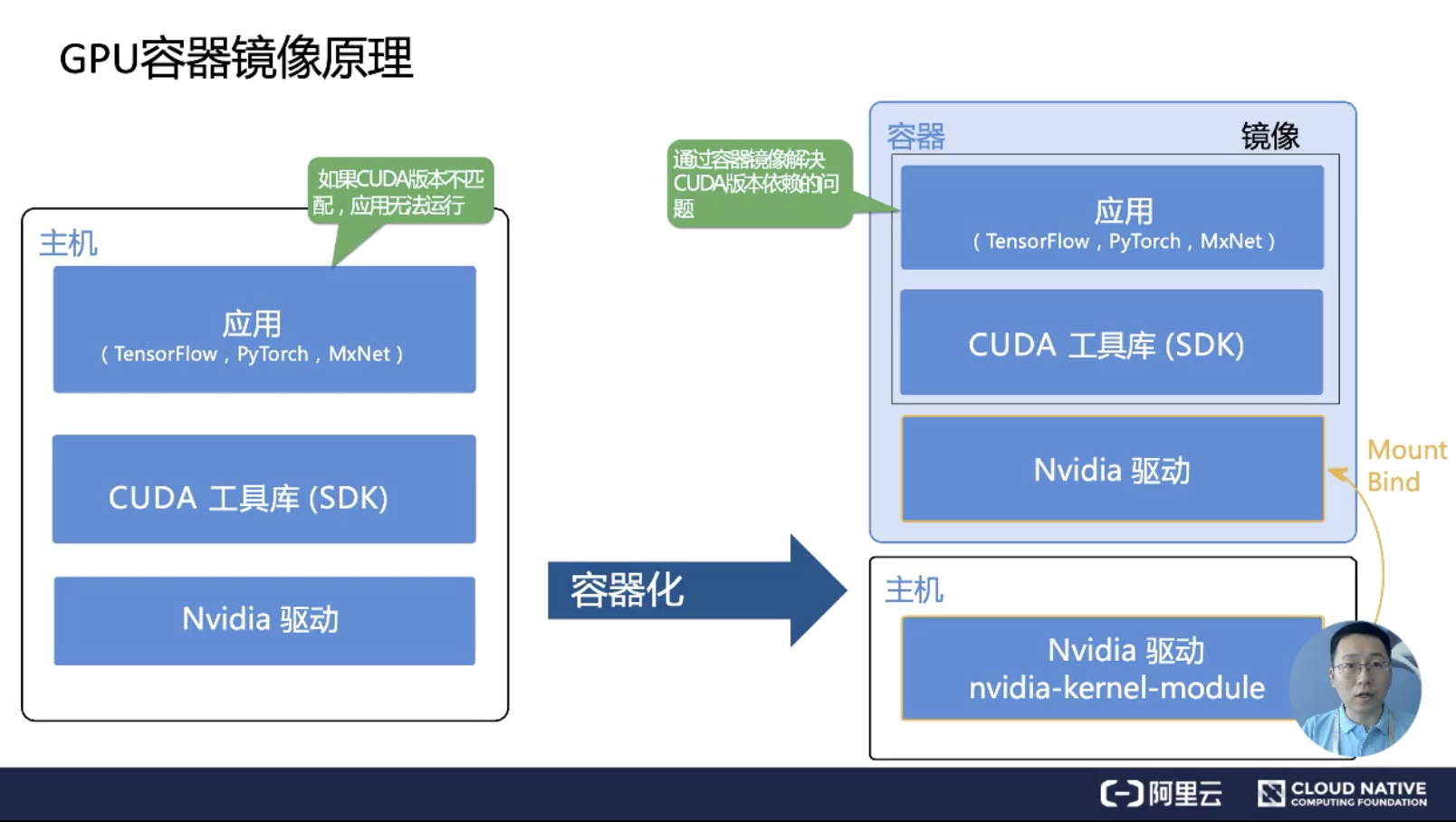
GPU container
a gpu containeris needs to map NVIDIA driver from host to the container, which is now done by nvidia-docker; the other issue is gpu-based app usually has its own (runtime) libs, which needs to install in the containers. e.g. CUDA, deep learning libs, OpengGL/vulkan libs.
k8s device plugin
k8s has default device plugin model to support gpu, fpga e.t.c devices, but it’s in progress, nvidia has a branch to support gpu as device plugin in k8s.
nvidia docker mechanism
when application call cuda/vulkan API/libs, it further goes to cuda/vulkan runtime, which further ask operations on GPU devices.
cloud DevOps
simulation in cloud
so far, there are plenty of cloud simulation online, e.g. ali, tencent, huawei/octopus, Cognata. so how these products work? all of them has containerized. as our test said, only Tesla GPU is a good one for containers, especially for rendering needs; GeForce GPU requires DISPLAY or physical monitor to be used for rendering.
cloud vendors for carmakers
as cloud simulation is heavily infrastructure based, OEMs and cloud suppliers are coming together:
- FAW -> Ali cloud
- GAC -> Tencent Cloud
- SAC -> Ali cloud / fin-shine
- Geely -> Ali cloud
- Changan -> Ali cloud
- GWM -> Ali cloud
- Xpeng, Nio (?)
- PonyAI/WeRide (?)
obviously, Ali cloud has a major benefit among carmakers, which actually give Ali cloud new industry to deep in. traditionally, carmakers doesn’t have strong DevOps team, but now there is a change.
we can see the changing, as connected vehicles service, sharing cars, MaaS, autonomous vehicles are more and more requring a strong DevOps team. but not the leaders in carmakers realize yet.
fin-shine
SAC cloud, which is a great example for other carmakers to study. basically they are building the common cloud service independently.
- container service <– k8s/docker
- storage <– hdfs/ceph
- big data <– hadoop/sql
- middleware
- applications <– AI, simulation
it’s an IP for SAC, but on the other hand, to maintain a stable and user-friendly cloud infrastructure is not easy at all.
refer
openGL direct hardware rendering on Linux
tips for runing headless unity from a script
Unity Server instance without 3d graphics